
How AI Generates: From Noise to Form
The story of how diffusion models create—and what they leave behind

The AI-Generated Tennis Player
A few minutes before the 2025 US Open final, I was getting ready to watch it on TV. Arthur Ashe Stadium glowed under the lights, shapes and sounds just beginning to coalesce, a walk from noise to form. This wasn’t just a match. Something bigger was unfolding.
Carlos Alcaraz and Jannik Sinner had split the last two Grand Slam finals. This was the rubber match. Every tennis fan felt the weight.
Then, just before the first serve, the broadcasters flashed IBM’s AI prediction:
Alcaraz: 53% Sinner: 47%
Two precise numbers from a confident algorithm. I flinched.
It wasn’t the numbers that bothered me. It was what they signaled: the quiet seep of machine logic into spaces once ruled by instinct. “AI Insights” had become a regular feature of the broadcast, but this time it felt different. As if the match had already been played. As if probabilities were facts.
Then a line from the commentators snapped into focus. The McEnroe brothers were reminiscing about earlier rounds when one of them recalled something Alexander Bublik had said before his match with Sinner:
“He’s like an AI-generated player.”
If you know Bublik, you know he wasn’t being cruel, just half-joking and half-marveling. Even if you’ve never followed tennis, the phrase carries weight: what does it mean to call a human “AI-generated”?
A few days earlier, I’d been at the US Open grounds for Arthur Ashe Kids’ Day. The stadium buzzed with summer energy: autograph lines, bouncing tennis balls, music echoing off the courts. Amid the carnival, I wandered over to the practice sessions. Sinner and Alcaraz were both hitting.
The contrast was immediate.


Sinner’s session was clinical: shot after shot with the same rhythm and depth, mesmerizing in its precision, almost machine-like. His cap pulled low, as if to keep his emotions hidden from the crowd.
Alcaraz, by contrast, looked like he was playing jazz. He swung freely, threw in drop shots mid-rally, shifted pace without warning. He grinned at the audience. His game wasn’t about minimizing error. It was about exploring possibility.
In hindsight, that scene gave Bublik’s line a sharper edge. It wasn’t just a metaphor. It was a diagnosis. A way of naming a game that had become too clean and too legible. Like many machine learning systems, trained to optimize themselves out of surprise.
And you notice this pattern elsewhere too: in football, between Ronaldo’s sculpted consistency and Messi’s improvisational genius; in mathematics, between methodical solvers and intuitive leapers. It isn’t just tennis, it’s a wider rhythm of how intelligence expresses itself.
And once you hear that phrase—AI-generated—you start to see it everywhere. In sports. In art. In work. In ourselves.
But what does it actually mean?
To truly answer this requires an understanding of the two principal methods of modern machine learning: prediction and generation. The initial IBM stat, the one that felt so unsettling, was a product of the former. Sinner, in his game, embodies the latter.
The Anatomy of Simple AI
Let’s start with the simplest version of prediction: supervised learning from labeled examples. IBM’s 53% wasn’t a glimpse into the future, it was a reflection of the past compressed into numbers. And that’s the heart of predictive AI.
The system hadn’t watched them practice. It hadn’t seen the fluidity of Sinner’s backhand or the rhythm of Alcaraz’s court movement. Instead, it had to translate the messy reality of a tennis match into numbers. Every match from the past became a long sequence of entries: win/loss, surface type, serve percentages, head-to-head records. Collect them all, and they form what mathematicians call a “vector in a high-dimensional space.” The world was recast in a language the machine could understand.
But a sea of numbers is meaningless on its own. To make sense of it, the machine needs a lens—a model that can relate inputs to outcomes.
The model is the system’s best guess about how the numbers relate. You can picture it as a lens with thousands of tiny knobs—its weights—that determine what it pays attention to. At first, those settings are random. The model doesn't know a thing about tennis.
This is where the data comes in. The machine is fed thousands of historical matches, each one a labeled example of a win or a loss. The model makes a prediction, uses the labels to compare it to the correct outcome, and learns from its mistake. Every error is a clue, telling the algorithm to slightly adjust a setting. Wrong again? Adjust the weights. Closer this time? Nudge them.
This simple feedback loop—prediction → error → adjustment—repeats over and over.
Eventually, the model’s weights settle into a shape that separates wins from losses in its internal space. It doesn’t memorize matches, it learns the statistical patterns that define them. That’s why it can make an educated guess about the Alcaraz–Sinner final, a match it had never seen before.
This is the essence of supervised prediction.1 But such prediction has its limits. And as we’ll see, generative models also predict, though what they predict is not outcomes, but the structure of data itself.
Watching the match, I realized those numbers had no feel for rhythm, the very thing tennis is made of. A model can weigh serves and surfaces, but it cannot hear the music of a rally.
The Shape Behind the Shadows
A model can tell you who’s likely to win the next match, but it cannot invent a new player. For that, we need a different kind of learning.
Predictive models divide the world into categories: cats or dogs, winners or losers. Their accuracy depends on a quiet assumption—that the examples we see are not arbitrary, but drawn from some underlying source that generates them in predictable ways. Think of it as a hidden well. We never see the well itself, only the drops it produces. And our faith in prediction comes from believing the next drop will resemble the last.
Generative modeling takes that background belief and makes it the task. There are no labels, no outcomes, just fragments, like relics from a lost civilization. The goal is not to sort them, but to reconstruct the source they came from. Not perfectly, but well enough that we can draw from it too.
This is the generative leap: from dataset to distribution, from what is to what could have been. If you’re handed five lines of poetry, your job is not to repeat them, but to write the sixth, in the same voice. The model must learn not just to recognize style, but to continue it. To generate something original, yet familiar.
There is no teacher, no answer key. The only feedback is the structure already present in the data. With the right tools, the model can trace that structure backward—not to the true source, perhaps, but to a plausible one. And once that fiction is in place—a hidden shape behind the shadows—something remarkable happens: the model begins to create.
Over the past decade, different families of models have tried this leap. Generative Adversarial Networks (GANs) turned it into a game of deception: one model creates, another critiques. Variational Autoencoders (VAEs) compressed the world into latent codes, balancing abstraction with reconstruction. Both made bold moves, but with limits: GANs unstable, VAEs blurry.
Then came a different idea altogether: an approach built not on guessing, but on restoration. Less like classification, more like remembering how something could have been formed.
A Walk from Noise to Form
Start with an image: a street scene or a painting. Now imagine a ritual that slowly corrodes it: each step adds a whisper of numerical static. Remember, the image is just a long list of numbers, and each number is nudged a little further into disorder until, at last, the picture dissolves into pure randomness. Nothing remains but noise.
In diffusion models, this is called the forward process—a walk from form to noise.
Now comes the crucial part: training. It’s a bit like a game. At each stage of corruption, we pause and give the model a noisy image. Then we ask a single question: What noise was added here?
The model doesn’t have to guess the whole image. It just has to figure out the layer of static on top. Once it makes a guess, we compare it to the true noise we added, and adjust the model accordingly.
In effect, image generation becomes a labeled learning problem, just like the tennis example above. A predictive model maps match features to outcomes; a diffusion model maps corrupted images to the noise that was added. The original image acts as a hidden label, used to compute the noise, but the model never sees it directly.
During training, the model sees millions of real images: faces, animals, cities, textures, symbols. From this vast corpus it doesn’t memorize, but absorbs the patterns of the world: what looks typical, what combinations of pixels feel natural.
So when it denoises, it isn’t merely removing static, it’s replacing uncertainty with plausibility. A blurry arc near a circle might be an eye. Wetness pools near curbs. A symmetry hints at a human face. Each training image teaches the model what real looks like, even when buried in chaos.
Training teaches more than denoising—it teaches choice. Each image could be reconstructed in many plausible ways, so the model learns to hold a space of possibilities. Variance, the deliberate noise, forces the model to imagine, not merely recall. Each sample becomes a different walk from static to structure, guided by plausibility rather than memory.
Once trained, the model walks in reverse. It begins not with an image but with static: no edges, no objects, no structure. Then, step by step, it removes the kind of noise it believes would be there if a real image were hidden beneath. Each subtraction brings the canvas closer to coherence. What emerges isn’t a memory, it’s a possibility.

This works because the forward process was engineered with care. Each corruption step is mild, smooth, and reversible, so the model doesn’t need to solve the entire problem at once. It only answers the same question again and again: What noise is here? An impossible task becomes a thousand solvable ones. The loop is the same: Input → Prediction → Error → Adjustment. But here, the input is noise. And the label? Derived from the noise we added.
Generation, too, is guessing. One step. Then another. Each subtracts what doesn’t belong.
It struck me then how close this was to Sinner’s game. Each stroke pared away uncertainty, until only the most predictable pattern remained. Beautiful, precise, and vulnerable to someone who thrives in the chaos he worked so hard to erase.
A Technical Aside: What Noise?
If you’re wondering why diffusion models learn to predict the noise and not the clean image directly, there’s a beautiful mathematical reason.
By choosing a special kind of noise, Gaussian, the entire forward process becomes transparent. Each corruption step has a closed-form description, and the reverse step can also be modeled as Gaussian. That means the model’s task reduces to something elegant: estimating the mean of a Gaussian distribution, step by step.
This isn’t a hack. It’s mathematically equivalent to maximum likelihood training. What looks like a daunting density estimation problem collapses into a sequence of regression tasks—predict the added noise—each solvable with standard supervised learning.
You don’t need this detail to appreciate how diffusion works. But it’s there beneath the surface, a quiet trick of probability theory that turns chaos into art.
The Architects of the Dream
Up to this point, we’ve focused on how diffusion models walk back from noise: reconstructing structure from randomness, one step at a time. But how does the model know what kind of structure to reconstruct?
This is where prompts come in. A prompt doesn’t dictate the shot, it tilts the whole rally. Without it, the model is like a player hitting freely in practice: forehands, backhands, serves, drop shots, all mixed together. Add a prompt, and it’s like a coach calling out: “Work on your cross-court forehand.” The practice narrows and the strokes become guided.
Technically, this blending of free play and guided drills is a type of classifier-free guidance. The model is trained both with prompts (practice to order) and without them (free hitting). At generation time, it mixes the two, leaning more or less toward the “coached” shot. The balance is tunable, just as a player can move fluidly between structure and improvisation.
Noise is the fog of an empty practice court, and the prompt is the coach’s voice calling through it. The model walks toward structure, but the voice tilts the whole map. In the movie Inception, architects planted the scaffolding of a dream and let it unfold; prompts play a similar role, shaping possibility without dictating its outcome.
A Glitch in the Matrix
Even as diffusion models grow uncannily precise, their limits surface in surreal ways. The most famous glitch? The six-fingered hand. A portrait looks flawless—skin tones, lighting, style—until the palm reveals an extra finger. Not grotesque. Just… wrong. But plausibly wrong. After all, six-fingered hands do exist, but vanishingly rarely. A model that produces them isn’t reasoning about anatomy. It’s sampling surface variance without understanding structure.
A similar failure happens with something as trivial as a calendar. At first glance, it looks right.
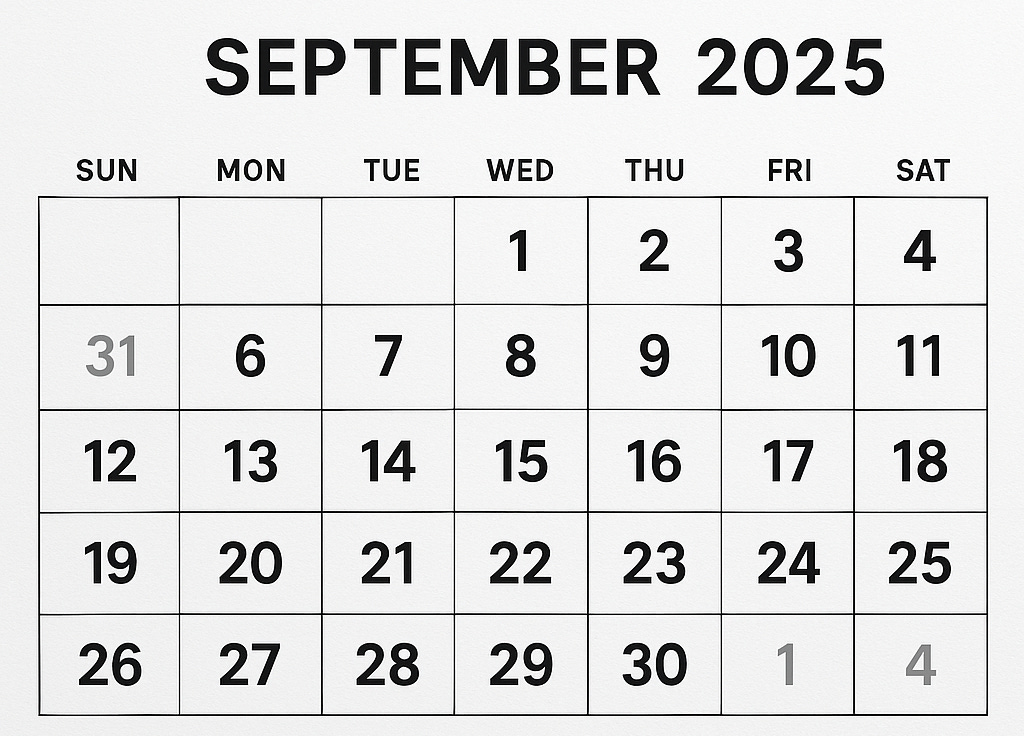
A generative AI’s attempt to “draw a calendar for September 2025.” Notice how August 31 sneaks in, October 1 and 4 show up, and the grid is uneven. What should have been a trivial, rule-bound task collapses into surface-level plausibility.
Why does this happen? Because the model hasn’t learned what a hand is or what a calendar means. It has only learned what they look like. Its world is built from surfaces and co-occurrences, not from structures and functions.
So why not just fix it? Why not hard-code a rule: “hands must have five fingers” and be done with it? Two problems get in the way.
First, there’s a representation gap. The constraints we care about—five fingers, proper anatomy, physical feasibility—live in a space of meanings. But generative models operate in a space of numbers: vectors, pixel intensities, gradients. There’s no knob labeled “finger count.” In tennis, a coach can say “aim cross-court,” and the player adjusts by feel. But no coach can demand a serve at “exactly 87 mph, with 2,500 RPM, landing six inches above the net.” The instruction doesn’t map cleanly.
Second, there’s a terrain problem. The forward and reverse processes of diffusion are efficient because the mathematical space they operate in is smooth and predictable. But enforcing a hard constraint is like leaving this flat training court for mountainous terrain. Every step through noise must now be taken on a rugged, curved surface shaped by anatomy or logic. The path slows, errors accumulate, and what was a smooth probabilistic walk becomes a painful climb.
Prompts, in contrast, are soft. They tilt the distribution like a coach’s gentle nudge. But hard constraints slice it. And in doing so, they expose the mismatch between what models represent and what we mean.
The six-fingered hand isn’t just a glitch. It’s a scar, a reminder of the gap between surface and meaning, and of the cost of forcing logic onto spaces never built to bear it.
My Yale colleague Phil Bernstein has made a similar point about architecture: these models can conjure photorealistic façades, but they “can’t draw a damn floor plan with any degree of coherence.” Surfaces they mimic; structures they miss.
From Optimization to Awareness
And so, under the closed roof at Arthur Ashe, Alcaraz beat Sinner in four sets 6–2, 3–6, 6–1, 6–4. Something was haunting about the loss, especially on the very surface where Sinner has reigned for the past two years. It wasn’t the defeat itself; Alcaraz had beaten him before. It was how Sinner lost. He played cleanly, stayed consistent, and stuck to his game plan. And still, it wasn’t enough.
After the match, Sinner gave one of the most self-aware press conferences I’ve ever heard from a top athlete. He didn’t blame the conditions or his health. He blamed predictability.
“I was very predictable today on court,” he admitted. “He did many things, he changed up the game… Now it’s going to be on me if I want to make changes or not.”
Then came something truly rare:
“I’m going to aim to maybe lose some matches from now on… trying to be a bit more unpredictable as a player.”
That line stayed with me. In it, you could hear a player pushing against the edge of his own formation.
Sinner, by all accounts, came up through a highly structured path: disciplined, optimized, drilled. It gave him precision and control, qualities that make him almost untouchable when in rhythm. His groundstrokes are among the cleanest in the game, an artistry of consistency that’s made his rise remarkable.
Yet that very strength can become a trap. The same qualities that make him formidable also make him, at times, too legible. Watching him, it wasn’t hard to see what Alexander Bublik meant when he called Sinner an “AI-generated player.” The comment wasn’t about artificiality; it was about legibility—how cleanly his game seemed to emerge from accumulated data. When it worked, it was seamless. When it failed, it failed by doing exactly what it had been trained to do.
Alcaraz, by contrast, is harder to predict not because he’s random, but because he plays from a different encoding. Even seasoned commentators struggle to compare him. He’s not Federer, not Nadal, not Djokovic. His game doesn’t feel inherited; it feels invented. Erratic, yes, but that volatility is part of the threat. He doesn’t rely on pre-learned sequences. He responds to the moment. You don’t know what’s coming next, because he may not either. He plays on instinct, on feel, on joy.
Sinner spoke about needing to make his game less predictable. In machine-learning language, it sounded like injecting “variance”: a tweak, a regularization trick. Still optimization, just with noise. Like a model trying to escape overfitting.
But Alcaraz wasn’t just jittering parameters. He was playing with awareness. A drop shot no one expected. A change of pace no statistic could anticipate. To be clear, I’m not proposing a new AI model here. Awareness, as I’m using it, isn’t an architecture but a metaphor, a way of naming the difference between optimizing within patterns and stepping outside them.
This is the real divergence—not just between two players, but between two architectures of intelligence. Generative models, like players, are solving optimization problems on the data. But their ability to generate depends entirely on how the past is represented. Encode the past as statistical surface patterns, and the future will look like repetition. Encode it through structure, through attention, through presence, and the space of generation changes.
That’s the deeper lesson, one that extends far beyond tennis. One architecture learns through replication: layering consistency until mastery is achieved. The other learns through friction, exploration, and surprise. Both are powerful. But they encode the past differently. And what they generate—on court, on canvas, in code—depends on what they remember, and how.
In machines, we choose the representation. In people, it is shaped by culture, feedback, and presence. And perhaps by what we choose not to optimize.
So the question isn’t just who won the match. It’s: What kind of intelligence are we building?
And what kind are we becoming?
For an accessible introduction to the math behind machine learning, see Anil Ananthaswamy’s recent book, Why Machines Learn.
Thanks again for this piece. Your final question of what kind of intelligence are we becoming has me asking what do I want to be? As someone who has followed a Sinner-esque approach of structure and discipline, I now find myself desiring and seeking more randomness.
I really enjoyed the tennis part of this piece, Mr. Vishnoi. The way you compared Sinner’s precision with Alcaraz’s improvisation made prediction versus generation click for me. The line about Sinner being “too predictable” really stayed with me because it felt like the same trap AI models fall into when they overfit. It made the whole essay resonate on both a technical and personal level.